序
我去,这才是我最接近 AK 的一次呃呃……
内存外置
负责存储数据的 DM 和指令的 IM 并不是 CPU 的一部分,因此我们需要将其从 CPU 架构中移除。
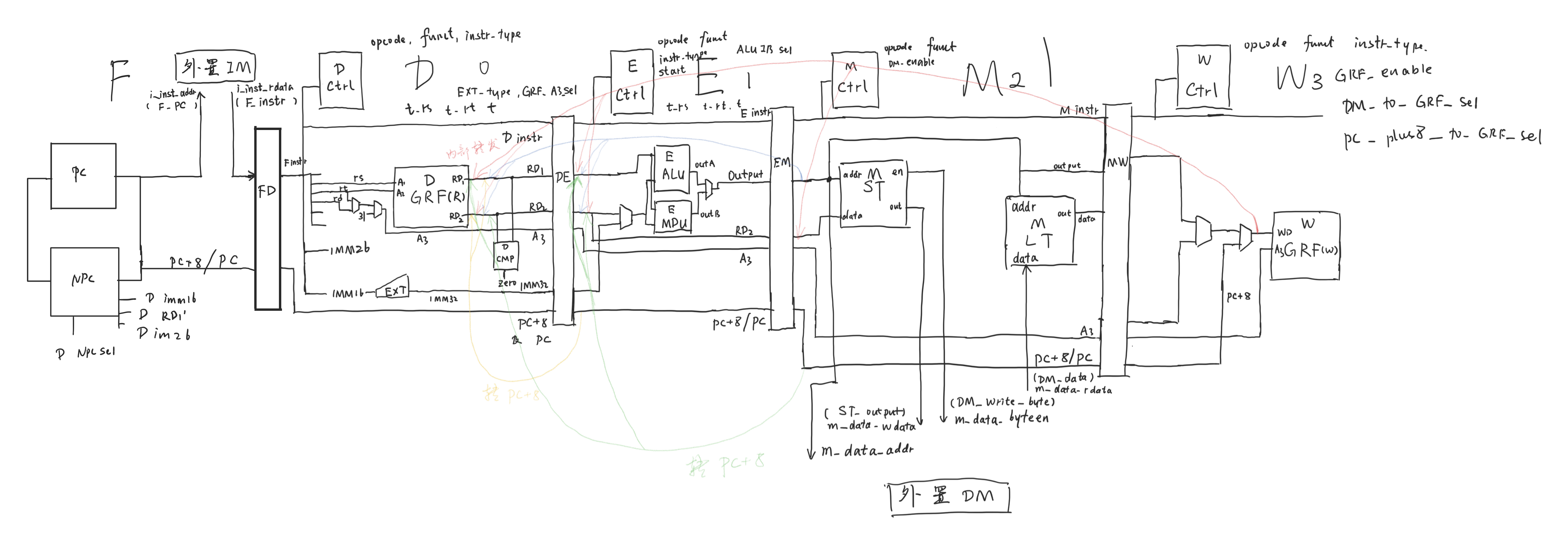
新增的设计草稿
已实现指令:
1 | add, sub, and, or, slt, sltu, lui |
设计 MDU
MDU 与 ALU 并列存在于 E 级,负责计算和乘除法相关指令,以及读写 HI 和 LO 两个寄存器。端口定义如下:
| 名称 | 种类 | 位宽 | 方向 | 备注 |
|---|---|---|---|---|
| clk | wire | 1 | I | 时钟信号 |
| reset | wire | 1 | I | 同步复位信号 |
| inputA | wire | 31:0 | I | 第一个操作数 |
| inputB | wire | 31:0 | I | 第二个操作数 |
| instr_type | wire | 5:0 | I | 指令种类 |
| start | wire | 1 | I | start 为 1 时,MDU 开始运算,并将 busy 置为 1 若干周期 |
| outputB | wire | 31:0 | O | MDU 输出结果,视情况与 ALU 输出的 outputA 进行选择 |
| busy | wire | 1 | O | MDU 使用中信号。当其为 1 时,阻塞所有需要用到 MDU 的指令 |
修改 ST
ST 是我原来的为 DM 设计的预处理模块。因为 DM 外置,因此需要进行修改。将写入 DM 的使能信号改为 4 位宽,分别对应 4 个字节的写入使能,这样就能实现 sb st 等功能。
思考题
-
为什么需要有单独的乘除法部件而不是整合进 ALU?为何需要有独立的 HI、LO 寄存器?
答:乘除法运算时间长,且计算结果不需要立刻写入 GRF 或 DM 中。如果整合进 ALU,效率低下。HI 和 LO 独立保存乘除法结果,不会立即使用,即在计算中不影响 ALU 的正常流水。 -
真实的流水线 CPU 是如何使用实现乘除法的?请查阅相关资料进行简单说明。
答:首先CPU会初始化三个通用寄存器用来存放被乘数,乘数,部分积的二进制数,部分积寄存器初始化为 0。然后在判断乘数寄存器的低位是低电平还是高电平:如果为低(0)则将乘数寄存器右移一位,同时将部分积寄存器也右移一位,乘数寄存器低位溢出的一位丢弃,部分积寄存器低位溢出的一位填充到乘数寄存器的高位,同时部分积寄存器高位补 0。如果为 1 则将部分积寄存器加上被乘数寄存器,在进移位操作。
当所有乘数位处理完成后部分积寄存器做高位乘数寄存器做低位就是最终乘法结果。 -
请结合自己的实现分析,你是如何处理 Busy 信号带来的周期阻塞的?
答:首先busy信号只影响进入 MDU 的指令。故需要在 Controller 输出一个判断当前指令是否为进入 MDU 指令的信号D_is_mult。MDU 负责根据正在起作用的指令进行倒计时,计时结束前 busy 均为 1,用(D_ismult && (E_start || E_busy))这个条件来判断是否进行阻塞。 -
请问采用字节使能信号的方式处理写指令有什么好处?(提示:从清晰性、统一性等角度考虑)
答:首先第 n 位使能信号为 1 就表明第 n 字节需要写入,形成一一映射关系,很清晰。其次对于所有关于按字节/半字写入的指令,都有统一的提供使能信号的方式,提高了扩展性。 -
请思考,我们在按字节读和按字节写时,实际从 DM 获得的数据和向 DM 写入的数据是否是一字节?在什么情况下我们按字节读和按字节写的效率会高于按字读和按字写呢?
答:不是。需要高频进行按字节读写时效率更高。 -
为了对抗复杂性你采取了哪些抽象和规范手段?这些手段在译码和处理数据冲突的时候有什么样的特点与帮助?
答:严格按照流水级进行信号的命名,这样方便在信号多的时候分清楚级次。为易混淆的信号增加特殊的命名,比如写入 DM 的数据和 写入 GRF 的数据都能用data表示,就分别用DM_data GRF_data表示。 -
在本实验中你遇到了哪些不同指令类型组合产生的冲突?你又是如何解决的?相应的测试样例是什么样的?
答:
两条计算指令紧邻时的情况,转发:
1 | addi $t0, $t0, 0x00000001 |
一条访存类指令紧跟一条计算类指令的情况,阻塞:
1 | lw $t0, 0($0) |
-
如果你是手动构造的样例,请说明构造策略,说明你的测试程序如何保证覆盖了所有需要测试的情况;如果你是完全随机生成的测试样例,请思考完全随机的测试程序有何不足之处;如果你在生成测试样例时采用了特殊的策略,比如构造连续数据冒险序列,请你描述一下你使用的策略如何结合了随机性达到强测的效果。
答:使用随机生成的测试数据,可能出现阻塞,转发的触发情况测试不足等问题,需要自行增加一些相关的测试。
测试
1 | # ========================================== |
第一题 MUJICA
MUJICA,全称 Mask Update Joint Immediate Conditional Add
细节 Mask,细节 Update,细节 Joint,细节 Immediate,细节 Conditional,细节 Add。
| 31:26 | 25:21 | 20:16 | 15:0 |
|---|---|---|---|
| opcode | rs | rt | immediate |
| 110100 |
mujica rs rt immediate
RTL 如下:
不说了,期待第三季。
(ps: P6 第一次上机有一题叫 MYGO)
第二题 BOTTO
| 31:26 | 25:21 | 20:16 | 15:0 |
|---|---|---|---|
| opcode | rs | rt | offset |
| 011011 |
botto rs rt offset
RTL 如下:
汉明距离的定义是:
其中 的定义同第一题,即两数 , 值不同的位的个数。
这题是条件跳转 + 写入寄存器地址悬空。
我的做法是在 D 级计算 hd,以及决定是否跳转(输出相应的 zero 给 NPC)。由于写入寄存器的可能性有两种,要写入的数据也不同,于是添加了一个 wire [1:0] botto_sel,与 hd 一起流水到 E 级进入 ALU。在 ALU 中进行判断要写入的是哪一种结果。然后声明一个 E_exact_A3,在 E 级指令是 botto 的情况下根据 botto_sel 来决定写入 GPR[rs] 或 GPR[rt],将 E_exact_A3 替换原来的 E_A3 进入流水级寄存器,一直给到 W 级。
仍旧注意算术右移的实现,记得加 $signed()。
第三题 LWCM
| 31:26 | 25:21 | 20:16 | 15:0 |
|---|---|---|---|
| opcode | base | rt | offset |
| 111001 |
lwcm rt offset(base)
本题要求在 M 级加入一个新的 32 位寄存器 WD。WD 在初始化和复位后变成 32'h0,只有 lwcm 可以对其进行读写。
RTL 如下:
WD 可以像流水级寄存器那样做一个模块来实现,需要有 clk reset input output,具体逻辑和流水级寄存器一样。
然后是执行 lwcm 指令的时候无条件写入 memWord,因此 input 当 M 级指令为 lwcm 的时候为 memWord,否则为 WD 本身的 output,保持其不变。
memWord 和 WD 的比较结果作为一个信号来改变 M_exact_A3,流给 W 级。实现方法如同第二题。
阻塞的时候需要特判,否则会 TLE。
唉唉,这题我最后一个点出 bug,也不是 TLE,最后也没 de 出来,伤心。看群里说的可能跟 == 比较的两个数中混入了 x 值有关,现在也无从考证了,这题用的 MARS 是课程组魔改中的魔改版,也不可能拿得到。
P7 加油吧,计组实验终于要结束了~