序
仍旧猛攻 1h第三题未通过。不过所幸 P5 这道鬼门关一次过了,题也都抄下来了。
设计草稿
设计架构
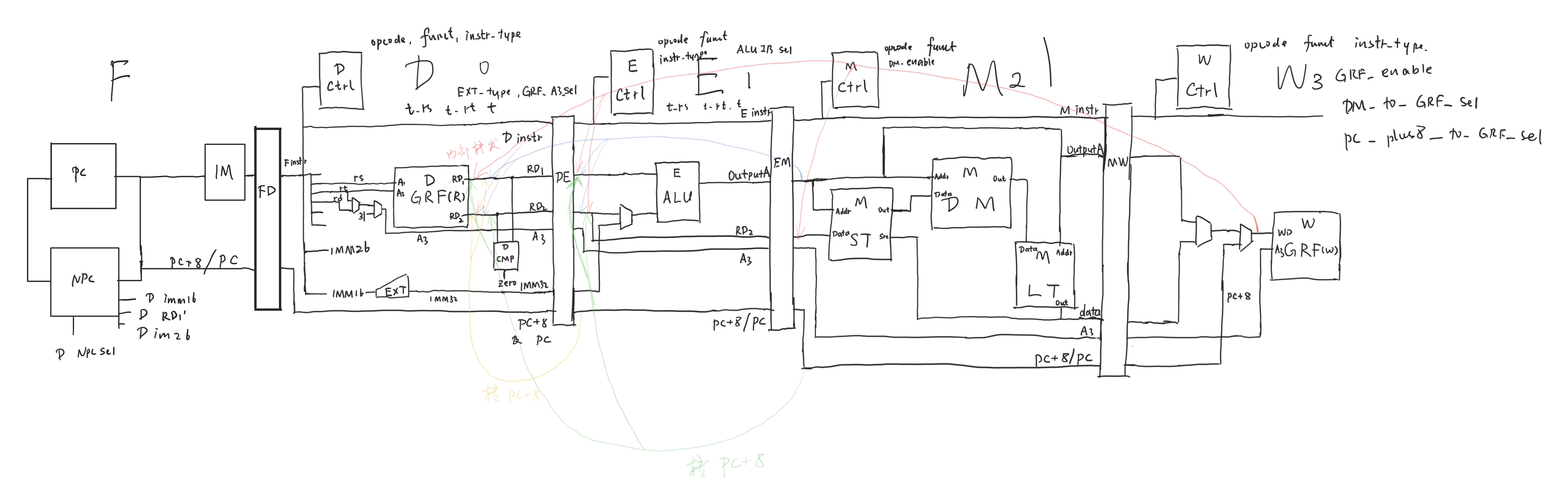
修改 NPC
由于延迟槽的存在,在执行 beq bne 等时,其在 D 级才会判断是否发生跳转。此时 F 级的 PC 为 D 级的 PC + 4。故当 D 级确定发生跳转时,NPC 只需要计算 F_PC + offset || 2’b00 即可,因为 F_PC = D_PC + 4。
将 PC + 8 流水至 W 级
由于延迟槽的存在,执行 jal jalr 等需要把 PC + 8 存入 GRF。这时就需要将 PC + 8 流水到 W 级。
修改 Controller
定义 D E M W 级编号为 0 1 2 3,相邻流水级之间时间差为 1。
某级到 D 级的时间差为其编号。
新增端口如下:
| 名称 | 类型 | 方向 | 位宽 | 备注 |
|---|---|---|---|---|
| t_rs | wire | O | 3:0 | 指令在 D 级,再经过多少时间使用 GPR[rs],缺省为 4’hf |
| t_rt | wire | O | 3:0 | 指令在 D 级,再经过多少时间使用 GPR[rt],缺省为 4’hf |
| t | wire | O | 3:0 | 能产生新数据的指令在 D 级,再经过多少时间算出新数据并能转发,缺省为 4’hf |
转发需要在流水级寄存器后。
为每个流水级实例化一个 Controller,内部计算每种指令的 t_rs, t_rt 和 t。例如:
-
add:
t_rs= 4’h1(E 级 ALU 需要使用)
t_rt= 4’h1(E 级 ALU 需要使用)
t= 4’h2(EMReg 后可以转发) -
beq:
t_rs= 4’h0(D 级 CMP 需要使用)
t_rt= 4’h0(D 级 CMP 需要使用)
t= 4’hf(不产生新数据)
提取 CMP 至 D 级
从 ALU 中分离 zero 的运算逻辑,独立为一个 CMP 模块,放在 D 级。这是由于延迟槽的存在,beq 等相对跳转指令可以在 D 级计算是否需要跳转,让下一条指令(延迟槽)进入 F 级。故需要把 zero 运算逻辑提前到 D 级。
| 名称 | 类型 | 方向 | 位宽 | 备注 |
|---|---|---|---|---|
| inputA | wire | I | 31:0 | 第一个输入 |
| inputB | wire | I | 31:0 | 第二个输入 |
| type | wire | I | 5:0 | 指令种类信号,用以决定 CMP 比较逻辑,与 Controller 中定义一致 |
| zero | wire | O | 1 | 为 1 时发生相对跳转 |
转发
需求者:D 级 RD1 和 RD2(给 CMP)。E 级 RD1 和 RD2(给 ALU)。
供给者:E 级 PC + 8(jal 等),M 级 PC + 8(jal 等),EM 寄存器 outputA(来自 ALU),WD(包括 PC + 8 等多种可能)。
转发路线:从后往前的所有组合情况。
tuse 和 tnew
-
X 级 的 tuse:指令在 X 级,还剩多少时间要使用 rs 或 rt。指令每经过一级,该数字要减一。
-
X 级的 tnew:指令在 X 级,还剩多少时间可以转发新算出的数据。指令每经过一级,该数字要减一。
它们均等于某指令的 t_rs/t_rt/t 减掉 X 级的编号。即到 D 级的时间差。
判断转发条件
-
要发送的是否是 PC + 8
-
起点流水级携带的目标寄存器不是 3. 起点流水级携带的目标寄存器与终点的寄存器为同一个
-
终点 tuse,起点 tnew 存在
-
tuse >= tnew,即后一条指令使用时间晚于或等于前一条指令产生时间
阻塞
实现方式:
-
保持 PC:PC_en 置为 0。
-
保持 FD 寄存器:FD_en 置为 0。
-
插入
nop:清空 DE 寄存器,DE_clr 置为 1。
判断阻塞条件
-
起点流水级携带的目标寄存器不是 2. 起点流水级携带的目标寄存器与终点的寄存器为同一个
-
终点 tuse,起点 tnew 存在
-
tuse < tnew,即后一条指令使用时间早于前一条指令产生时间
当一条指令进入 D 级时即可判定需不需要阻塞,故只需要看转发到 D 级的可行性即可。
清空延迟槽
这在 RTL 中常表现为一个名为 NullifyCurrentInstruction() 的函数。当满足清空延迟槽的条件时(比如 CMP 来判断是否需要清空延迟槽),需要引出一个信号 null_signal。当非阻塞且清空延迟槽时,清空 FD 寄存器。即:
1 | assign FD_clr = (!stall && null_signal) ? 1 : 0; |
GRF 写使能悬空
一条指令,在运算之后才能判断它最终是否要进行写寄存器的操作(比如在 CMP 进行比较或在 ALU 运算),则需要引一个信号一直流水到 W 级。用这个信号结合使能信号来判断最终是否允许写 GRF。对于悬空的 t 值等,同样需要用这个信号来判断存在与否。
或者检测到这个信号之后,将写入地址之间换成 0 号寄存器,流水到 W 级。
GRF 写目标悬空
一条指令,在运算后才能得知最终写入的寄存器是哪一个。一般来说,是在 M 级算出这个地址(最大化减小阻塞的出现),在 M 级定义一个 M_exact_write_addr,替换原来的 M_write_addr,将其流水到 W 级。
然后修改转发路径中所有用到了 M_write_addr 的地方,改为 M_exact_write_addr。注意如果要写的内容和 PC + 8 无关,那么关于 PC + 8 的转发路径中的 M_write_addr 不要改。
阻塞的方法
然后为阻塞增加条件。由于运算地址是 M 级算出,那么该指令在 E 级时无从得知要写入哪个寄存器。这时后对于 D 级的指令,如果不是 j jal 这种不用寄存器的,则必须考虑是否要将其阻塞到 D 级。一般来说可以暴力阻塞(如果 E 级指令是xxx,则 stall 置为 1),或着考虑 D 级可能用到哪些会冲突的寄存器,按情况阻塞(比如已知 E 级指令要用到的只可能是奇数号寄存器,那么当 D 级指令要用奇数号寄存器时阻塞,用偶数时可以不阻塞)。该指令在 M 级的时候,阻塞的判断条件中要用 M_exact_write_addr。
思考题
-
我们使用提前分支判断的方法尽早产生结果来减少因不确定而带来的开销,但实际上这种方法并非总能提高效率,请从流水线冒险的角度思考其原因并给出一个指令序列的例子。
答:当发生数据冒险且无法通过转发来解决时,发生阻塞,一方面没有数据传给 D 级供 CMP 计算,一方面 PC 值被锁定,此时即使 CMP 算出了比较结果回传给 NPC,仍需要等阻塞结束才能更改 PC 值,导致效率没有提升。例如:
1 | lw $t0, 0($0) |
-
因为延迟槽的存在,对于 jal 等需要将指令地址写入寄存器的指令,要写回 PC + 8,请思考为什么这样设计?
答:分支或跳转指令在 D 级提供新的 PC 值,此时下一条指令已经进入 F 级。如果决定发生跳转,那么 F 级的工作无效,浪费资源。因此需要开启延迟槽来使得流水线效率最大化。此时对于jal等,跳转到的指令应该是延迟槽的下一条,即 PC + 8。 -
我们要求大家所有转发数据都来源于流水寄存器而不能是功能部件(如 DM 、 ALU ),请思考为什么?
答:如果在功能部件后转发,若不考虑数据在导线中传递的时间,则转发终点接收到数据的时间是一个时钟周期的中间或者末尾,而它仍需要花时间进行计算。即有可能在计算过程中遇到下一个时钟上升沿,传出的数据仍是错误数据。而从流水级寄存器出发,保证了转发重点是在一个周期的开始接收到数据。 -
我们为什么要使用 GPR 内部转发?该如何实现?
答:如果 W 级写入的目标寄存器是 D 级读取的目标寄存器,那么 D 级应当读取 W 级写入的新数据,然后把该数据写入目标寄存器。此时发生内部转发。
实现:设计两条数据通路D_RD1_from_W和D_RD2_from_W,条件是写入地址不为 0,写入地址和读取地址相等,终点 tuse,起点 tnew 均存在,tuse >= tnew -
我们转发时数据的需求者和供给者可能来源于哪些位置?共有哪些转发数据通路?
答:需求者:D 级 RD1 和 RD2(给 CMP)。E 级 RD1 和 RD2(给 ALU)。供给者:E 级 PC + 8(jal 等),M 级 PC + 8(jal 等),EM 寄存器 outputA(来自 ALU),WD(包括 PC + 8 等多种可能)。转发路线:从后往前的所有组合情况。 -
在课上测试时,我们需要你现场实现新的指令,对于这些新的指令,你可能需要在原有的数据通路上做哪些扩展或修改?提示:你可以对指令进行分类,思考每一类指令可能修改或扩展哪些位置。
答:计算类:首先在 Controller 为其添加对应的控制信号。添加该指令的 t_rs, t_rt, t。然后在 ALU 添加相应的运算逻辑。
跳转类:首先在 Controller 为其添加对应的控制信号。添加该指令的 t_rs, t_rt, t。在 CMP 添加比较逻辑。在 NPC 添加 PC 的更新逻辑。 -
简要描述你的译码器架构,并思考该架构的优势以及不足。
答:采用分布式译码,每一个流水级实例化一个 Controller。这降低了流水级之间传递的信号数量,减少编码量。但 Controller 数量多增加复杂度。译码风格是控制信号驱动型,即根据机器码识别出指令后,将其添加到各个控制信号产生的条件中。指令数量较多时适用,且代码量易于压缩,缺陷是如错添或漏添了某条指令,很难锁定出现错误的位置。
测试
1 | # MIPS 5-Stage Pipeline Stress Test (No Dead Loop) |
第一题 DSC
| 31:26 | 25:21 | 20:16 | 15:0 |
|---|---|---|---|
| opcode | rs | rt | immediate |
| 011000 |
dsc rs, rt, imm
给 逻辑左移 immediate 15 至 11 位的值,算术右移 4 至 0 位的值,二者异或存入 。
RTL 如下:
首先这题很阴,它要用的是 rt 和 imm16,要写的是 rs。这与一般反过来了。我考场的做法是临时给 GRF 的写入地址 MUX 增加 rs,然后给 ALU 开一个新的输入端 imm16,方法比较简单粗暴。
室友提供了一种优雅的写法,即如果 D 级检测到指令是 DSC 时,直接给 rs 和 rt 调换顺序,并让 ALU 的 inputB 端口读入 imm16。
还有一点是注意算术右移的实现。在 Verilog 中,>>> 表示算术右移,但如果第二个运算数(要移动的位数)无符号,那么 >>> 会退化成 >>。记得加上 $signed
第二题 BLOC
| 31:26 | 25:21 | 20:16 | 15:0 |
|---|---|---|---|
| opcode | rs | rt | offset |
| 111111 |
bloc rs, rt, offset
计算 的前导 1,如果个数大于 的 5 至 0 位(无符号比较),则跳转。否则顺序执行。无条件将 PC + 8 写入 $ra。
RTL 如下:
判断逻辑在 CMP 中执行。使用组合逻辑求得前导 1 个数。注意是无符号比较。注意是无条件写入 PC + 8,因此 GRF 写使能可以保持打开。注意在转发 PC + 8 的判断条件里面加入这条指令(E 级和 M 级)。
第三题 LHP
| 31:26 | 25:21 | 20:16 | 15:0 |
|---|---|---|---|
| opcode | base | rt | offset |
| 111111 |
lhp rt, offset(base)
读 Data Memory 中一个字,与 异或。如果结果高 16 位等于低 16 位,那么计算 highest 作为 GRF 写入地址,否则写入 $ra。
RTL 如下:
考试的时候逻辑写完之后就导致原来的指令无法正常使用了,没 de 出来 bug,等后续研究一下。