序
这是北京航空航天大学计算机学院 2025 年计算机组成原理预习部分的 MIPS 汇编部分。
IDE
MARS(MIPS ASSEMBLER AND RUNTIME SIMULATOR)
MARS 是一个轻量级的、用于教学的 MIPS 汇编语言集成开发环境(IDE)。它由密苏里州立大学开发,基于 Java 环境运行,完全绿色且免费。我们的课程即使用此软件来进行 MIPS 汇编语言的学习、编写和运行。
寄存器简介
什么是寄存器?
寄存器是一种高速存储器,可以暂存指令、数据、地址等。CPU 中只有有限的寄存器可供使用。
MIPS 体系结构中,CPU 对数据的操作是基于寄存器的。内存中的数据需要先使用读取类指令(Load)保存到寄存器中才可使用;操作完成的数据也需要使用装载类指令(Store)保存到内存中。
MIPS 中的 32 个通用寄存器
所谓通用寄存器(General - Purpose Register, GPR),代表它没有明确规定的用途,程序员可以随意对他们赋值、取值,同时他们的值也可以直接参与到各种指令之中。
然而,虽然冠有通用的头衔,程序员们还是会以一定的规则来使用它们,这是为了便于程序员之间的交流,同时也是为编译器等工具定下了一定的标准。
| Registers | Name | Usage |
|---|---|---|
| $0 | $zero | 常量0 |
| $1 | $at | 保留给汇编器使用的临时变量 |
| $2-$3 | $v0-$v1 | 函数调用返回值 |
| $4-$7 | $a0-$a3 | 函数调用参数 |
| $8-$15 | $t0-$t7 | 临时变量 |
| $16-$23 | $s0-$s7 | 需要保存的变量 |
| $24-$25 | $t8-$t9 | 临时变量 |
| $26-$27 | $k0-$k1 | 留给操作系统使用 |
| $28 | $gp | 全局指针 |
| $29 | $sp | 堆栈指针 |
| $30 | $fp | 帧指针 |
| $31 | $ra | 返回地址 |
$0一般不能用于赋值。即对其赋值不违反语法,但其始终保持为 0。$1保留给汇编器,一般不使用它。
三个特殊寄存器
-
PC(Program Counter):它用于存储当前 CPU 正在执行的指令在内存中的地址。
-
HI:这个寄存器用于乘除法。它被用来存放每次乘法结果的高 32 位,也被用来存放除法结果的余数。
-
LO:HI 的孪生兄弟。它被用来存放每次乘法结果的低 32 位,也被用来存放除法结果的商。
MIPS 汇编指令集架构
什么是指令?
指令,即是由处理器指令集架构(Instruction Set Architecture,可以理解为计算机体系结构中对程序相关的部分所做的定义)定义的处理器的独立操作,这个操作一般是运算、存储、读取等。一个指令在 CPU 中真正的存在形式是高低电平,也可以理解为由 01 序列组成的机器码。但因为机器码人类难以阅读和理解,所以指令一般由汇编语言来表示,也就是我们俗称的汇编指令。从这个角度上来说,汇编指令只是指令的一种表示形式而已,其实质是一样的。
指令之格式
指令一般由一个指令名开头,后跟其操作数,中间由空格或逗号隔开。操作数一般为 0 至 3 个,且每个指令名有其固定的操作数。一般来说格式如下:
指令名 操作数 1 操作数 2 操作数 3
或:
指令名 操作数 1, 操作数 3(操作数 2)
操作数可以是寄存器、立即数[1]或标签[2]。每个指令都有其固定的对操作数形式的要求。而标签最终会由汇编器转换为立即数。
常见指令格式样例:
1 | add $s0, $a0, $a1 |
前文提到可以用标签代替某个地址,正如上例第 4 行的 loop 标签。
注意:在 MARS 中,跳转指令只能使用标签来进行跳转,不能使用立即数!
机器码指令
机器码
计算机只能理解二进制形式的数据。而我们前面所说的汇编语言,最终就会转化为机器语言——也就是机器码指令, CPU 可以直接识别这种机器语言,从而去完成相应的操作。
MIPS 汇编中,所有的指令长度均为 32 位,即 4 字节,或者说 1 字。
一段汇编语言可以转换为一段机器码,例如下面这段汇编指令:
1 |
|
其转换后的结果为(16 进制):
1 | 20080064 |
机器码之指令格式
-
R 型指令
R 型指令的操作数最多,一般用于运算指令。例如add、sub、sll等。其格式如下(左侧为高位,右侧为低位,第二行为位数):
| op | rs | rt | rd | shamt | func |
|---|---|---|---|---|---|
| 6 | 5 | 5 | 5 | 5 | 6 |
-
I 型指令型指令的特点是有 16 位的立即数(偏移也是一样的道理)。因此,I 型指令一般用于
addi、subi、ori等与立即数相运算的指令(这里需要注意:在写汇编语言的时候,需要使用负号来标记负数,而不要和机器码一样认为首位的 1 就代表负数),或beq、bgtz等比较跳转指令,因为它们要让两个寄存器的值相比并让 PC 偏移 offset 这么多,刚好利用了全部的字段。还有存取指令,例如sw、lw,它们在使用时需要对地址指定一个偏移值,也会用到立即数字段。
| op | rs | rt | offset or immediate |
|---|---|---|---|
| 6 | 5 | 5 | 16 |
-
J 型指令
J 型指令很少,常见的为j和jal。他们需要直接跳转至某个地址,而非利用当前的 PC 值加上偏移量计算出新的地址,因此需要的位数较多。
| op | address |
|---|---|
| 6 | 26 |
严格来说,并非所有的指令都严格遵守上面三种格式,有的如 eret、syscall 指令一样没有操作数;有的如 jalr 指令一样某些字段被固定为某个值。不过,就大部分指令而言,都可按上面三种格式进行解释
-
表格解释
- op:也称 opcode、操作码,用于标识指令的功能。CPU 需要通过这个字段来识别这是一条什么指令。不过,由于 op 只有 6 位,不足以表示所有的 MIPS 指令,因此在 R 型指令中,有 func 字段来辅助它的功能。
- func: 辅助 op 识别指令。
- rs, rt, rd: 通用寄存器的代号,并不单指某一寄存器。范围是
$0~$31,用机器码表示就是 00000~11111。 - shamt: 移位数,用于移位指令。
- offset: 地址偏移量。
- immediate: 立即数。
- address: 跳转目标地址,用于跳转指令。
扩展指令和伪指令
扩展指令(Pseudo Instruction)
对基本指令的转写(例如用标签代替立即数),或对操作数的略写等,被称作扩展指令。
扩展指令的功能主要是简化程序。汇编器将一些常用、但标准指令集不提供的功能封装为一条指令;或者改变现有指令的操作数的形式或个数,使其以新的形式出现。需要注意的是,它们只是形式上是一条新指令,而实际上,在汇编器将其汇编之后,还是使用标准指令来实现的。
最常用到的一条扩展指令是 li 指令,它用来为某个寄存器赋值,比如 li $a0,100 就是将 100 赋给 $a0 寄存器。汇编器在翻译这条扩展指令时会根据需要,将它翻译成不同的基本指令或基本指令的组合。譬如:
-
所赋的值少于等于 16 位,则等价于用
addiu指令,比如addiu $a0, %0, 0x00001000。 -
所赋的值大于 16 位,则等价于用
lui和ori指令,即先将高 16 位装在在寄存器的前面,再用或运算补充低 16 位,比如lui $a1, 0x00001234和ori $a0, $a1, 0x00004321。
另一条常用的扩展指令是 la 指令,这条指令与 li 指令非常类似,都是为寄存器赋值,只不过是使用标签来为寄存器赋值。经过了前面的学习,大家应该已经知道标签本质上对应一个 32 位地址,但 li 指令并不能直接使用标签来为寄存器赋值,必须要使用 la。比如 la $t0, fibs 这条指令就是把 fibs 这个标签的地址存入 $t0 中。
伪指令(Directives)
伪指令(Directives)是用来指导汇编器如何处理程序的语句,有点类似于其他语言中的预处理命令。伪指令不是指令,它并不会被编译为机器码,但他却能影响其他指令的汇编结果。常用的伪指令有以下几个:
-
.data:用于预先存储数据的伪指令的开始标志。参数为address,表明数据的初始地址。若无参数,则初始地址设为默认地址。 -
.text:程序代码指令开始的标志。同上 -
.word:以字为单位存储数据。格式:[name]: .word [data1], [data2], ...,以字为单位连续存储数据data1, data2, ...初始地址保存在标签name当中。 -
.asciiz:以字节为单位存储字符串。末尾自动添加\0。格式:[name]: .asciiz "[content]",以字节为单位存储字符串,末尾以 NULL 结束,初始地址保存在标签name当中。
什么是以字节为单位存储字符串呢?举个例子,hello 中每个字母占用一个字节,然后 \0 占用一个字节(0x00)。
-
.space:申请若干个字节的未初始化的内存空间。格式:[name]: .space [n],申请 n 个字节未初始化的空间,初始地址保存在标签name当中。
.space n即申请 n 个字节的未初始化的内存空间。
MIPS 指令初步
位运算
四则运算是更复杂程序的基石,而位运算是四则运算的基石。
——麦瑟尔夫
本节介绍 and or xor nor andi ori xori 这几种位运算。
它们的格式都是 op rs, rt, rd,即把 rt 和 rd 两个寄存器的内容进行运算,运算结果存入 rs 寄存器。运算结果写前面。
首先是与运算、或运算、异或运算。正如其名,非常好懂。
然后是或非运算,有一个小技巧,就是要对一个寄存器取反,可以利用或非运算来完成(MIPS 指令集没有提供取反指令):
1 | nor $t0, $t0, $0 |
别忘了 $0 永远是 0。
如果需要把一个寄存器的值和一个立即数进行运算,则需要用到末尾带“i”的指令(即 immediate),正如与立即数、或立即数、异或立即数。
注意:使用立即数的指令,立即数必须写在第三位。
几条扩展指令
-
li:li rs, immediate,将立即数赋给寄存器。 -
move:move rs, rt, 将后一个寄存器的值赋给前一个寄存器。 -
la:la rd, label,将标签对应的地址(十六进制值)赋给寄存器,后续我们讨论地址和内存的细节内容。
加减法
本节介绍 add sub addu subu addi addiu 几种加减法运算。
四则运算和位运算相比多了两个棘手的问题,即符号和溢出。
首先来谈正负性的问题,其实这根本就不是个问题。如果你是补码领域大神的话,你就会发现,在不考虑位溢出的情况下(这里“不考虑位溢出”的意思是发生溢出时会将溢出位舍去,相反“考虑溢出”的意思是如果发生溢出直接报错),二进制补码的正负性其实是相同的,这也正是补码的优越之处。不信可以看看下面这些例子:
在 32 位的条件下,
0x3 + 0xffffffff的结果是多少?你的做法或许是这样的:首先,你发现0xffffffff的最高位是1,于是断定它是负数,将其一段操作转换成-1,再与0x3相加,得到结果0x2。但实际上,我直接把它们两个相加,结果就是0x100000002,舍去溢出的最高位,直接就得到了0x2。再举一个例子,同样是在 32 位的条件下,
0xfffffffd - 0xffffffff的结果是多少?细心的你可能会将这个式子转换成(-3) - (-1),结果是-2,也就是0xfffffffe。但是我不管正负,直接进行运算,发现被减数小于减数,我直接在被减数前面补一个溢出位 1 ,于是原式变成0x1fffffffd - 0xffffffff,结果等于0xfffffffe。摘自原书
这是 addu(无符号加) 和 subu(无符号减)的原理。因为它们把操作数当作无符号数直接运算,然后直接把溢出部分舍去。但是其运算结果还是有符号的!!!
而 add 和 sub 则不会简单地舍去溢出位,而是在溢出时抛出异常。如果使用这种运算,需要注意判断是否溢出。
此外 add 和 addu 也有它们的立即数版本 addi 和 addiu(注意不是 addui),而 subi 和 subiu 是伪指令,和上面一样它们也必须把立即数放在第三位。
乘除法
本节介绍 mult div mfhi mflo mthi mtlo 几种乘除法运算。
加减法至多只溢出一位,而乘除法则不然,两个 32 位数字相乘,结果可达 64 位,必须要用新的处理方法。
于是我们想到了之前提到的特殊寄存器 HI 和 LO,在乘法运算的时候,直接把高 32 位放到 HI 寄存器里面,低 32 位放到 LO 寄存器里面,就万事大吉了。用法 mult rs, rt,即把 rs 和 rt 两个寄存器的内容相乘。
为什么不要指定结果保存的位置?
因为结果放到了 HI 和 LO 里面,自然就只需要指定两个操作数的寄存器了。
这两个是特殊寄存器,不能直接调用,要想使用里面的数,必须提前取出来,这就是 mfhi 和 mflo 存在的意义。用 mfxx rs 把 HI 或者 LO 寄存器的值存入 rs 寄存器。
当然也有反过来的用法,即手动把数字写进 HI 和 LO 寄存器。用 mthi 和 mtlo 指令。用 mthi rs 把 rs 寄存器的值存入 HI 寄存器,用 mtlo rs 把 rs 寄存器的值存入 LO 寄存器。
除法也利用这两个寄存器,不过是 HI 存余数而 LO 存商。切勿记反。切勿记反。切勿记反。
若除数是负数,处理方法与 C 语言中相同:被除数为正数时,余数为 0 或正数;被除数为负数时,余数为 0 或负数。如下表:
| 被除数 | 除数 | 商 | 余数 |
|---|---|---|---|
| 7 | 3 | 2 | 1 |
| 7 | -3 | -2 | 1 |
| -7 | 3 | -2 | -1 |
| -7 | -3 | 2 | -1 |
几个单位
自此节开始要进入内存的学习,先通过了解单位来入门。
-
位(bit): 1 位代表 1 个 二进制值(0 或 1)。比如二进制数
0b10110就是 5 位。十六进制数0xabcd的每一个数字都能转换成 4 位二进制数,所以这个数是 16 位。 -
字节(byte): 8 位组成 1 个字节。一个 32 位的寄存器,其大小就是 4 字节。字节是地址的基本单位。
-
半字(halfword): 16 位组成 1 个半字。
-
字(word): 32 位组成 1 个字。
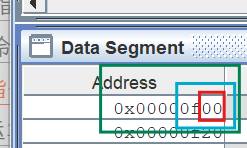
红色:8 位,1 字节蓝色:16 位,1 半字绿色:32 位,1 字
地址
内存空间连续而庞大,由于其连续,我们从 0 开始为其编号,称为地址。要注意每个地址代表的空间是 8 位,即一字节。也就是说字节是地址的基本单位。
举例来说,倘若要把数据 0x12345678 存储地址 0x0,那么按每个地址存入 8 位的逻辑,0x0 0x1 0x2 0x3 四个地址存入了 32 位,刚好存下这串数字。
小端存储
小端存储指的是数据的低位字节保存在内存的低地址中。以上面的存储为例,数据的低位字节是 0x78,保存在地址 0x0 中、0x56 存储在 0x1 中,以此类推。
大端存储
大端存储则相反,数据低位字节存储在内存的高地址中。此处不再举例。
按字访存
本节介绍 lw sw 两个访存指令。
顾名思义,上述两个指令表示 store word 和 load word,即向内存中存储或读取一个字。
sw rt, offset(rs) 表示将 rt 这个寄存器的内容写入 “rs 寄存器中储存的值 + offset 这个立即数或标签表示的地址”表示的地址处。
略微有点绕。举例而言,$t1 = 0x12345678 $t2 = 0x00000007,若要把 $t1 的值储存到地址 0x8 和 0x4 那么分别要如何写呢?
答案是:
1 | sw $t1, 1($t2) |
这就是所谓“表示的地址 + 偏移量”表示的地址。
要注意,括号中只能是一个寄存器。来看以下例子:
想要构建一个 int 类型数组,首地址为标签 arr,那么如何将 $t1 存入 arr[3] ?
首先我们要明确,int 类型是 4 字节,即一个数要占用 4 个地址。那么 arr[3] 的起始地址是 arr + 12。那么你有可能写成下面的形式:
1 | sw $t1, 12(arr) |
这就掉入了惯性思维的陷阱。arr 可以放在括号内吗?甚不然也。因为 arr 只是一个标签,而标签在编译时会被翻译成立即数,而立即数是不能放在括号内的。
正确的写法应该是:
1 | li $t2, 12 |
也就是说,先用一个寄存器把偏移量 12 保存下来,再加上 arr 标签得到 arr + 12,再用这个地址作为 sw 指令的第二个参数。
一般来说我们在括号里写基位置 base,括号外是偏移量 offset。但是这不是绝对的!上面我们就把偏移量写在内而基位置写在外,得到了一样的效果。
lw 要注意的事项与上面一致,只不过作用是把后面的地址中保存的值取到了前面的寄存器中。
注意:lw 和 sw 第二个参数计算出的地址必须合法(在内存范围内,且非负),且为 4 的倍数,否则会抛出异常!
与 move 和 la 的区别
这时候你可能会有疑惑:move $t1, $t2 和 lw $t1, 0($t2) 有区别吗?答案是有的。因为 move 做的是把第二个寄存器的值直接赋给第一个寄存器,而 lw 做的是根据第二个寄存器的值去内存空间找相应的地址保存的数据,再赋给第一个寄存器。
la 也是如此,la $t1, label 把标签表示的地址直接赋给了第一个寄存器,而 lw $t1, label($0) 则是根据标签表示的地址去内存中找到数据,赋给第一个寄存器。
也就是说,要注意地址和地址保存的数的区别。地址本身也是一串数,而这串数相当于一个门牌号,门后面就是这个地址保存的数。
按半字、字节访存
本节将介绍 sh lh sb lb 几个访存指令。
sh lh 全称 store halfword 和 load halfword,用于将一个半字(2 字节,16 位)从寄存器写入内存,或反过来。
sb lb 全称 store byte 和 load byte,用于将一个字节(8 位)从寄存器写入内存,或反过来。
这四条指令用法和 lw sw 一致,不再赘述。只有一些细节需要关注:
-
sh lh要求计算出的地址是 2 的倍数,而sb lb没有要求。 -
sh sb指令在将第一个寄存器的值存入内存中时,倘若寄存器中的值超过了标定的位数,则会将高位舍去,只存入低位。
比如$t1 = 0x12345678。现在执行sb $t1 offset(base),那么只有$t1中的低 8 位会被存入内存(0x78小端存储),高 24 位会被舍去。 -
lh lb指令在寄存器中已经有值的情况下往里面存数据时,会从低到高存入所需的数据,其余直接置 0。
比如$t1 = 0x12345678。现在执行lb $t1 offset(base)。如果地址保存的数是0xab,那么$t1的低 8 位会写入0xab而高 24 位直接置 0,即变成0x000000ab。
跳转指令
绝对跳转
本节将介绍 j jal jr jalr 几条跳转指令。
跳转指令有点像 C 语言中的 goto,可以将程序运行的位置跳转到指定位置。
j,即 jump,只有一种用法就是 j label,把label 写在目的地的前一行,就可以在运行完 j 指令后立即跳转到 label 处执行。
j 指令的目的地只能用 label 来表示,不能直接用立即数。
label 标识了目的地这行指令的地址。也就是说每写一行指令,都会转换成机器码在内存中保存,占用一个地址。前面所说 sw sh sb 指令会往内存写入数据,也占用地址。储存数据区和储存指令区是分开的,前者占用 0x00000000 - 0x00002fff 段,被称为 .data 段,后者占用 0x00003000 往后,被称作 .text 段。
MIPS 语言中的每条指令,转换为机器码都固定为 32 位,所以每条指令的地址 Address 也会按照顺序每条 +4 递增。
jal jr,是一对指令,需要同时出现。jal label 同样可以跳转到 label 对应的位置,但它会把当前指令的下一条指令的地址写入 31 号寄存器 $ra 中,即 PC + 4,PC 即当前指令的地址。jr $ra 则又回到 jal 的下一行继续执行。
理论上,jr 后可以接任意寄存器,它的作用本质上是将寄存器中的数当作地址,实现跳转。但一般和 jal 搭配使用。
为什么不跳回到 jal 的地址?
因为这样会导致 jal 再次执行,造成跳转的死循环。
jalr,是 jal 和 jr 的组合指令。jalr 要指定两个寄存器,用来保存 目的地 和 PC + 4,例如 jalr $t1, $t2 是跳转到 $t2 寄存器保存的地址,并把当前指令的下一条指令的地址写入 $t1 寄存器中。
相对跳转
本节将介绍 beq bne bgtz bgez bltz blez 几条条件跳转指令。
条件跳转指令的特点是可以根据一定的条件选择是否跳转。
beq,即 branch equal,表示当两个寄存器的值相等时,跳转到目的地。beq $t0, $t1, label。
相对应的是 bne 即 branch not equal,在 $t0 != $t1 时跳转。
除了等于比较,当然还有大于,小于比较。于是就有了 bgt(branch if greater than)、bge(branch if greater or equal)、blt(branch if less than)、ble(branch if less or equal)四条指令。
要注意,以上的指令是有符号比较的,如认为 0x0 大于 0xffffffff,于是又有了这四条指令的无符号变种,即 bgtu、bgeu、bltu、bleu。
有时候我们需要将寄存器的值和 0 比较,这很简单,只要把上述指令的第二个操作数用 $0 替换即可。但是 MIPS 提供了更优雅的处理方法:对于 beq bne bgt bge blt ble 这六条指令,在后面加上字母 z ,变成 beqz bnez bgtz bgez bltz blez ,就可以表示和 0 进行比较,相应地,第二个寄存器参数就被取消掉了。例如 bgez $t0, label 指令,就表示如果 $t0 寄存器中的值大于等于 0 ,则跳转到 label 标签所在的位置;否则不跳转。
(你问我为什么
bgtu bgeu bltu bleu后面不能加字母z?再仔细想想,你会为这个问题感到好笑的~)
考察相对跳转指令中,label 被翻译成了什么:
1 | li $s0, 1 |
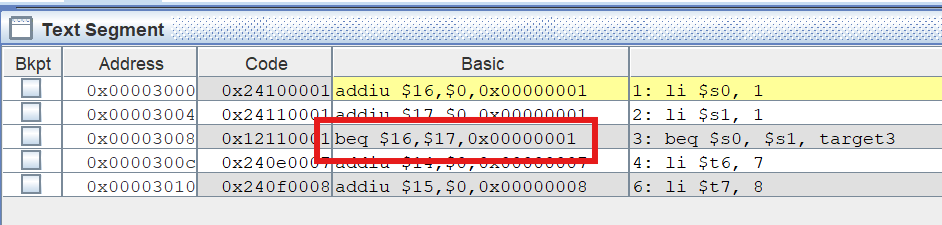
Amazing 啊,这个 target3 并没有像绝对跳转指令那样被翻译成了 li $t7, 8 这条指令的地址,而是一个神奇的 0x00000001。
原来,条件跳转指令又被叫做相对跳转指令不是没有原因的。它的目的地不是一个指令的地址,而是相对跳转指令和目的地之间的指令条数。
什么意思呢?上例中目的地是 target3,beq 和它中间隔了一条 li $t6, 7 指令,所以相对距离是 1。倘若二者中间再加一条 li $t5, 5 之类的指令,那么相对距离就变成 2。
移位运算
本节将介绍 sll srl sra sllv srlv srav lui 几条移位运算指令。
左移只有一种,那就是 shift left logical,sll。使用 sll $t1, $t0, imm5,即把 $t0 的数左移 imm5 位,结果存入 $t1。imm5 表示这个立即数最高只有 5 位,即左移的位数只能是 0 到 31。
右移情况则要复杂。它分为逻辑右移(高位补 0)和算术右移(高位补符号位)。逻辑右移的指令是 srl(shift right logical),算术右移的指令是 sra(shift right arithmetic),用法和 sll 指令完全相同。
除了以立即数为移动位数,还可以使用寄存器中的值作为移动位数。这就需要用到 sllv srlv srav 指令了。在使用指令时,将 imm5 替换为寄存器即可。如 sllv $t1, $t0, $s0 ,就是将 $t0 寄存器中的数据左移 $s0 寄存器中的数据这些位,存入 $t1 寄存器中。
倘若寄存器中的值超过了 5 位,那么会舍弃高位,只保留低 5 位作为移动位数。
最后是 lui 即 load upper immediate。它把一个立即数左移 16 位然后再写入寄存器,用法 lui $t0, imm16 。例如 lui $t0, 0x1234 的结果就是向 $t0 寄存器中写入 0x12340000 。
条件赋值
本节将介绍 slt sltu slti sltiu 几条条件赋值指令。
slt (set less than) 指令表示如果 $t0 中的值小于 $t1 中的值,则将 $t2 中的值设置为 1,否则设置为 0。
用法:slt $t2, $t0, $t1。
当然这也是有符号的比较,无符号变种是 sltu。除此之外还有和立即数比较的变种 slti 和 sltiu。
MIPS 语法
条件语句
对于下面这个简单的 C 语言条件语句:
1 | if (a > b) |
可以巧妙地利用跳转指令来在 MIPS 中实现:
1 | bgt $s0, $s1, branch1 # bgt: branch greater than, $s0 = a, $s1 = b |
简单来说,我们把 if 换成了 b 型跳转指令(相对跳转,因为 if 和其一样包含了条件判断),而 else 换成了 j 型跳转指令(前面已经做过条件判断了),从而实现分支的分离。
要注意,branch1 的结尾我们使用 j end 来强制脱离条件块,否则会进入 branch2。
如果增加一个分支,让 a == b 时把 a b 均设为 0,要如何写呢?
1 | bgt $s0, $s1, branch1 # $s0 = a, $s1 = b |
倘若条件判断更复杂,比如要同时满足两个条件(&&,与)或者至少满足一个条件(||,或)该怎么处理?
其实不难,如果要至少满足一个条件才能进入的代码块,我们可以让这几个条件满足时跳转到同一个分支:
1 | if (a > b || b > c) |
对应的 MIPS 代码如下:
1 | bgt $s0, $s1, branch1 |
如果是逻辑与,要怎么实现呢?毕竟一条指令只能判断一个条件,不能同时判断多个,比如下面的例子:
1 | if (a > b && b > c) |
其实我们不是非要把逻辑与写成 && 的样子,在 C 语言中我们要讲求代码编写的优雅,而在这里我们需要明晰其本质:
1 | if (a > b) |
就是说,两个条件只有都满足才能使 a = 0,其余情况都是 b = 0。用一个条件语句的嵌套来实现了这个效果:
1 | bgt $s0, $s1, branch1 # if outside |
循环语句
While
while 循环有两种写法,譬如下面的例子:
1 | a = 0; |
一种是“进入循环时条件跳转,离开循环时绝对跳转”:
1 | li $s0, 0 # a = 0 循环变量 |
这种写法在循环条件用 || 连接时很方便修改,只需要增加一个到 loop 的条件跳转指令即可。
一种是“进入循环时不跳转,离开循环时条件跳转”:
1 | li $s0, 0 # a = 0 循环变量 |
这种写法在循环条件用 && 连接时很方便修改,只需要增加一个到 end 的条件跳转指令即可。
这种写法相当于给循环条件取了个反。
For
for 循环可以等价转换成 while 循环,比如:
1 | for (int i = 0; i * i < n; i += 2) |
等价于:
1 | int i = 0; |
数组
一维数组
我们可以在 .data 段中开辟一段连续的内存空间作为数组存储数据。比如:
1 |
|
首先要注意 .space 开辟的空间是以字节为单位的。因此这里 array1 的大小为 20 字节,如果存储 int 类型的数据只能存储 5 个。
我们要存储的每个数据都要占据 4 个字节的空间(哪怕是只占据 1 字节的 char 型数据也建议直接用 4 字节来存储,我们的内存足够多,不需要担心不够用,使用 4 字节存储和寄存器的位数一致,也可以非常方便地使用 sw 和 lw 指令直接进行存取,也可以降低出错的概率。
array1 和 array2 两个标签在用 lw 或 sw 的时候都会被翻译成立即数,作为地址。实际上,它们代表的正是数组的首地址。在上面的例子中,若 .data 段是从 0x00000000 开始,那么 array1 就是 0x00000000,而 array2 就是 0x00000014(即十进制的 20)。因为 array1 占据了 0x00000000 到 0x00000013 的 20 字节空间,array2 就顺延下来了。
重申一次,最好保证在申请数组时,申请的字节数永远都能够被 4 整除!
要注意,访问数组中的值时,我们往往需要一个寄存器来保存数组的索引,这时候寄存器的值不应当是数组的下标,而是下标乘以 4 的结果。为简便计算,我们一般用位运算来计算,比如 sll $t1, $t0, 2 就可以将 $t0 中的值乘以 4 放入 $t1 中。
二维数组
我们知道二维数组在存储时其实是按照一位数组的格式来存的,即第一行、第二行、第三行……紧密排列。例如在一个 m 行 n 列的二维数组 matrix 中,matrix[i][j] 和 matrix[i * n + j] 并没有什么区别。所以 (i * n + j) * 4 就是访问 matrix[i][j] 的地址,即寄存器中保存的值。
字符串
字符以 ASCII 码的形式存储。
在内存中,字符是按照顺序从低地址到高地址排列的。比如 hello 这个字符串,其中 h 最先写入,并写入到这个字(即 4 字节)的最低位,假定为 0x00,那么 h e l l 分别就是 0x00 0x01 0x02 0x03,o 被保存到下一个字去,为 0x04。
有两条伪指令来写入字符串:
-
.asciiz
在字符数组末尾自动添加\0。 -
.ascii
不会自动添加\0。
和 C 语言一样,MIPS 字符串也要以 \0 结尾。
在
.data段要同时声明数组和字符串的情况,请记住一定要先声明数组,再声明字符串!道理其实很简单,因为如果先声明字符串的话,如果字符串的字节数不能被 4 整除,数组的首地址就又跑到不能被 4 整除的地方去了(叹气)。
一般地,能用 .asciiz 就别用 .ascii。
宏
宏的基本用法
宏定义用于把重复的代码简化成一条语句,比如:
1 | exit # or .macro exit() |
调用宏的时候只需要使用宏名即可,若无参数,则有无括号都可以,但你也可以为其添加参数:
1 | getoffset(%ans, %i, %j) |
这是一个计算每行 8 列的二维数组中第 i 行第 j 列的元素地址的宏。由于关于数组的代码需要大量地获取元素地址,这样的宏就可以大幅节约代码量。
事实上,宏中带 % 的参量可以表示一条指令的任何一个部分,比如立即数:
1 | store(%p) |
或者标签:
1 |
|
甚至指令名:
1 | instr(%i) |
当然,指令格式与宏定义的有差别的指令就不能用了,否则会报错。
还有宏内部的跳转:
1 | branch(%d) |
不可从宏内跳到宏外,反之亦然。
甚至可以嵌套:
1 | para(%p) |
宏出现循环调用(比如 para 调用自己,或 para 调用 instr,而 instr 又调用 para),就会报错。
宏实现函数
一般来说,我们约定俗成的参数寄存器是 $a0 $a1 $a2 $a3 这四个寄存器,分别存储函数的第 1、2、3、4 个参数。
若函数有返回值,我们有两种方法来用宏定义它:
-
要求一个参数填入寄存器来保存返回值。
-
宏定义内写死返回值保存的位置,外部用
move指令提取之。
第一种比如:
1 | my_add(%a, %b, %c) |
小技巧:$0 永远是 0,让它保存返回值,相当于没有返回值。
第二种:
1 | my_add(%a, %b) |
宏实现递归
首先明确一点,要在不同的函数栈上实现跳转,我们应该使用 jal jr 这对指令。在跳转时使用 jal,执行完后使用 jr 跳转回来。但是 jr 的目的地是 $ra 这个寄存器,专门保存 jal 的下一条指令的地址,让我们设想这样一个场景:
-
进入函数
f -
f中再次调用f -
第二层
f满足结束条件,回到第一层f -
第一层
f满足结束条件,回到主程序
f 的结构大致是这样的:
1 | jal f # 主程序调用 f |
乍一看非常之正确:主程序调用 f,f 执行到 jal f 后回到 f 的开头,满足条件跳转到 f_end,f_end 回到 jal 后一句,即 jr $ra,然后回到主程序。
对……对吗(
仔细一想,两个 jr 真能如愿跳转吗?实则不然。因为 $ra 只有一个,也就是说 $ra 的值是会被覆写的!!!
让我们再次分析:f 中第一次执行 jal 时,$ra 保存的是第一层中 jr $ra 这条指令的地址。第二层 f 中满足条件跳转到 f_end,然后回到了通过 jr $ra 回到了第一层的 jr $ra(有点绕),这里的 $ra 保存的仍然是第一层 jr $ra 的地址,也就是说原地 tp。
倘若递归次数更多,那么最后出现的情况就是 jr $ra 只能返回到最后一次调用 f 的位置,而不能如我们所想层层跳出。
所以我们需要用到栈来保存每层跳出的位置。
观察 MARS 界面右下角的寄存器界面,我们能够找到一个名为 $sp 的寄存器,它就是栈寄存器。和大多数寄存器不一样,它的初始值不是 0 ,而是 0x00002ffc。
操作系统中,栈是一个自顶向下的空间,先入栈的数据所在的地址反而大,后入栈的则小。
入栈实际上做了这么一件事:
1 | addi $sp, $sp, -4 # 栈顶指针向下移动 4 字节 |
出栈则是:
1 | lw $s0, 0($sp) # 从栈顶取出 $s0 |
在调用函数时,我更喜欢这样的出入栈方式:
1 | push(%r) |
即刚进入函数时就入栈,准备跳出函数前出栈。这样就能保证 $ra 始终保存的是正确的地址。同时,在递归函数内部存在多次调用自身的情况的时候,这种出入栈方式让你只用写一次出入栈指令。
还有一种如下:
1 | push(%r) |
所有像 $ra 这样,自身要用,子函数要用,子函数用完自己还要接着用的寄存器(即有覆盖风险的),都需要进行出入栈操作。全部共享一个栈空间(用 $sp 调度)。
系统调用
根据 $v0 的值不同,使用 syscall 命令的效果不同。以下是常用的调用命令:
| $v0 | 功能 | 要求或结果 |
|---|---|---|
| 1 | print integer | $a0 = 要打印的数 |
| 4 | print string | $a0 = 要打印的字符串(\0 结尾)地址 |
| 5 | read integer | $v0 = 读入的数 |
| 10 | exit program | / |
| 11 | print character | $a0 = 要打印的字符 |
| 12 | read character | $v0 = 读入的字符 |